
Dirty Pipe (CVE-2022-0847) proved that there is a new way to exploit Linux syscalls to write to files with a read-only privileges. The fact that someone can write to a file regardless of its permissions is a big security threat. An application of this vulnerability would be to write on the host from an unprivileged container. Keep in mind that this vulnerability is a kernel vulnerability which makes it hard, or even impossible, for user-mode runtime monitoring programs to detect this sort of file modification. In this blog we’ll show how Tracee, which is designed with a deep understanding of the Linux kernel, allows for runtime monitoring when this vulnerability would be exploited. We will detail how this vulnerability works, why it’s so unique, and how in-kernel technology like eBPF is still able to monitor writes that result from it.
Technical Breakdown of Dirty Pipe
File Copying Advancement in Linux
To copy a file with a naïve writing method, one needs to read the file (copy from kernel to user) and then write to a new file (copy from the user to the kernel).
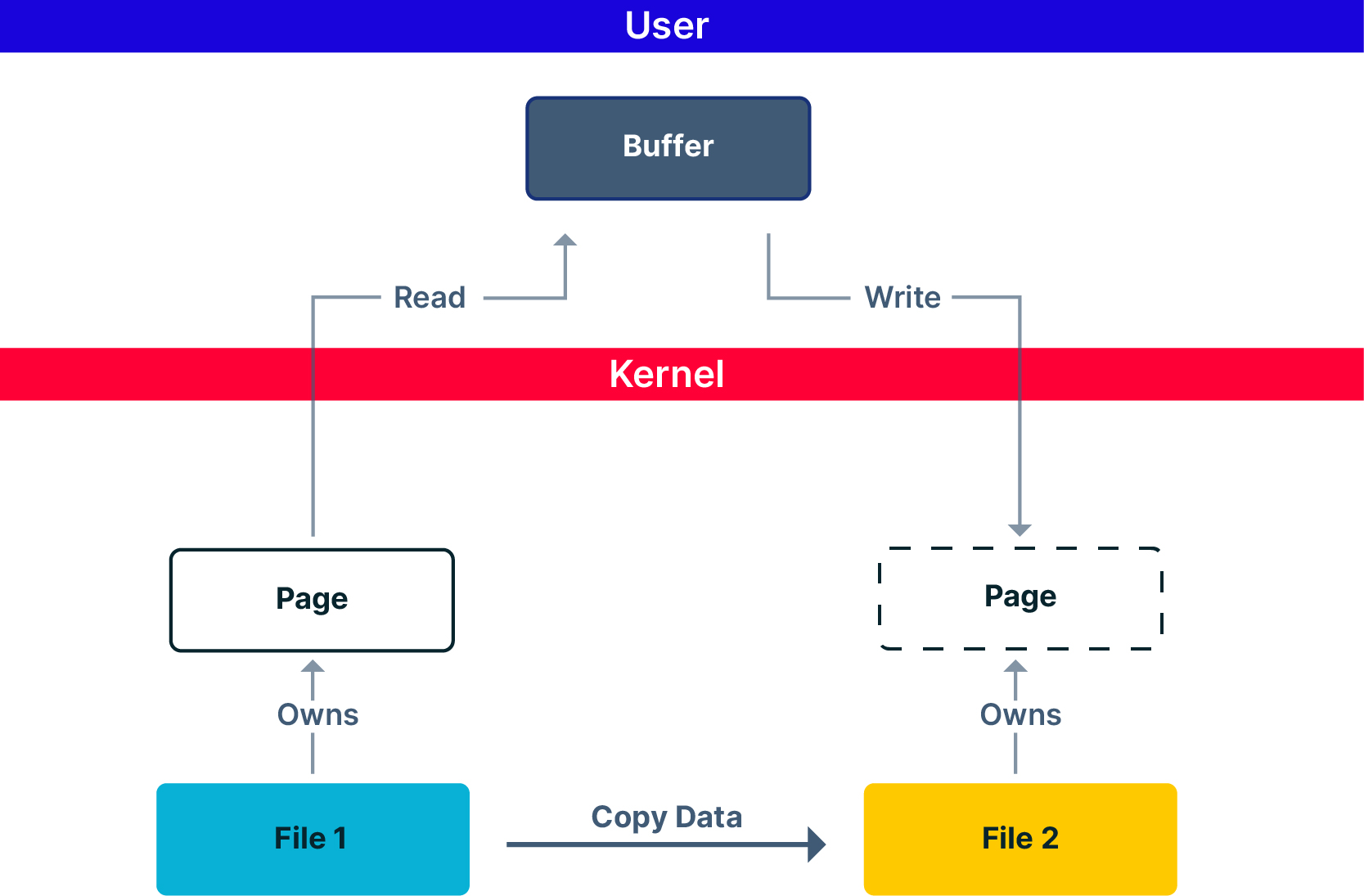
This method however is awfully “expensive” since you need to copy the entire data twice, while switching back and forth between spaces, only to move it between two objects in the kernel.
In kernel v2.2 the sendfile syscall was introduced followed by splice syscall in v2.5 and copy_file_range in v4.5. The purpose of all these syscalls is very simple – allow the user to copy from one file to another without moving through the user-mode, sparing the most expensive step of data transition between files. Reduced operations copy like the one described is called zero-copy. There are more implementations of this principle (like mmap etc.), but these examples are relevant syscalls for data transfer between two files.
Having said that, merely avoiding the operation of copying to and from the user-mode is still not enough to save computation power and space. Imagine copying a piece of data from one file in the disk to another (or hundreds) in your tempfs (so it is backed by memory instead of disk), and never modify it afterwards. Isn’t it a waste to copy the whole file content when it is already in the memory?
To address this issue, the kernel implemented a sophisticated idea – data copy will be issued only when one modifies a copied data. This might mean a real zero-copy – if no modification is completed then the system didn’t copy any data at all. So how is it done? The smallest memory block used by the kernel is the page. Thus, when transferring data, the kernel tends to do it in page units. When copying from one file to another using one of the above mentioned syscalls in a simplistic way, the kernel will copy pages from one file to another.
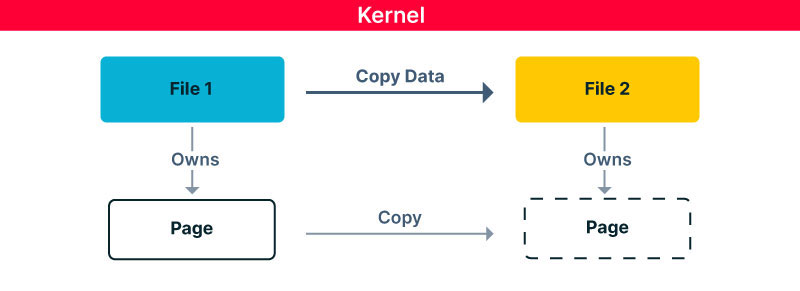
Therefore, to avoid copying until required, the kernel will not copy the page – it will copy a pointer to the page from one file to another. And, when a modification to the page is required by one of the files, the kernel will copy the data to a new page and modify it there. This concept is called Copy on Write (COW).
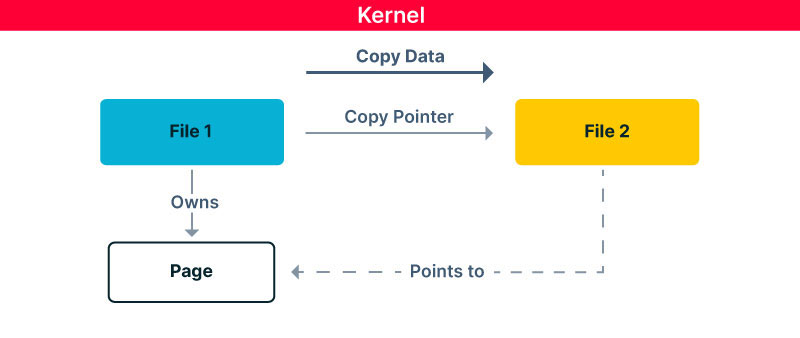
This feature is even more useful with the splice syscall. Splice is an operation of copying data between two files when at least one of them is a pipe. A pipe, a file whose read and write operations work in First In First Out (FIFO) order, is used broadly to move data between two processes or threads. This means that a pipe file’s data should never be modified because the pipe is only an intermediate station for the data transfer. In this case, when copying data into a pipe using splice, which is a zero-copy method, the kernel can safely copy a reference of the read file’s page to the pipe. In other words, splice to a pipe is a perfect zero-copy operation with minimal cost!
A deeper dive into pipes and splices
As mentioned above, pipe is a FIFO file, which is used broadly in communication between processes. From the kernel point-of-view, a pipe is an implementation of a file (aka file struct).
Files have many implementations to expose multiple types of data. Particularly in Linux almost all things in the system have file representations.
So, what are files?
Basically, files are system objects which allow data transfer to and/or from them. Usually, they should implement open operation to access them, and at least one of the read or write operations.
Thus, file access should look the following:
There are many more complicated operations that a file can implement, but we won’t go into details about these here.
A pipe object (pipe_inode_info struct) is implemented as a kind of a ring buffer. It contains internal buffers of the pipe_buf struct type (16 by default). The write and read of data to/from these buffers is circular. The pipe uses a method to follow the current reading buffer and writing buffer (the method changed between kernel versions).
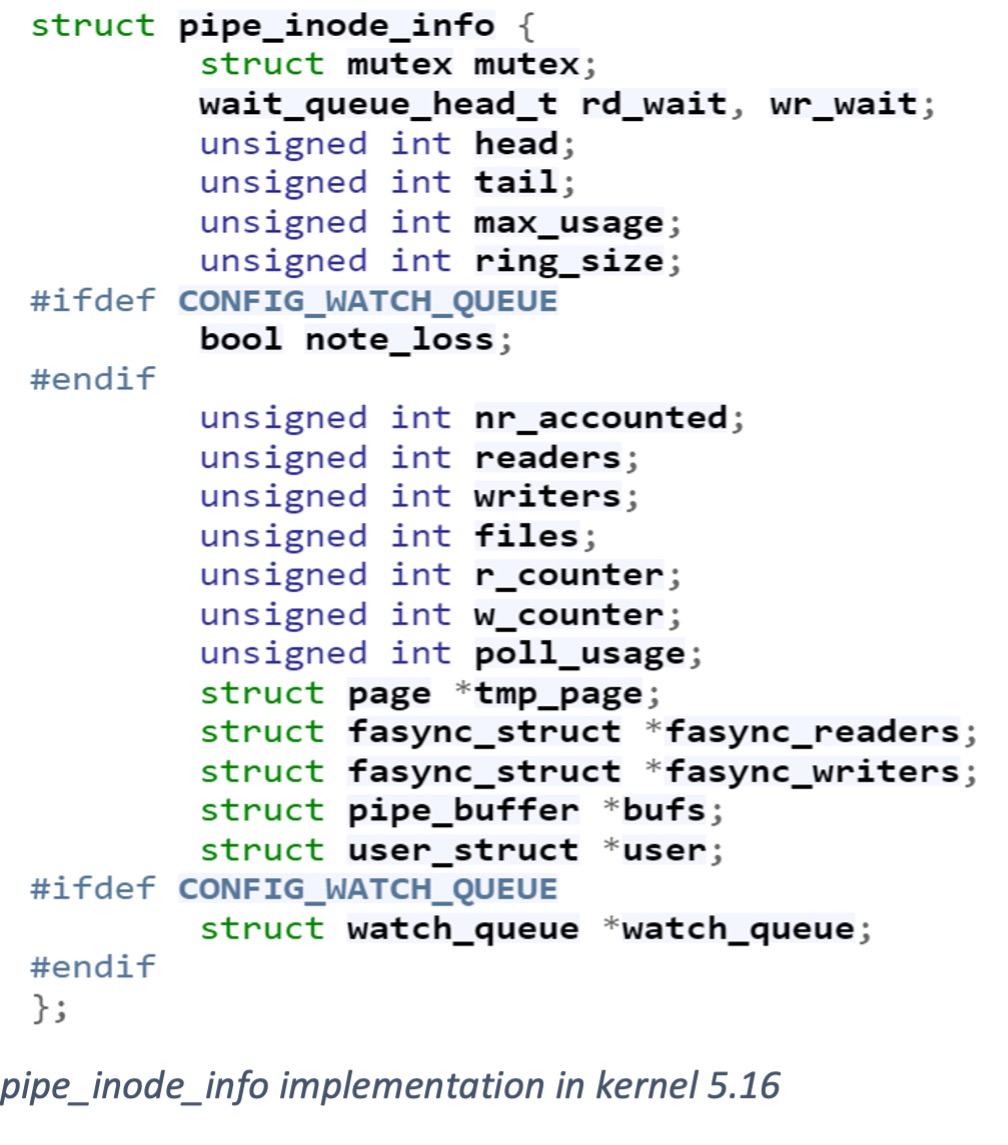
Pipe buffer’s implementation is a very simple struct, which contains a single page (for its data) and metadata, to manage this page.

Starting from kernel v5.8, the responsibility for protecting pages from modification (like in the case of zero-copy) moved to the pipe_buffer (previously it was part of the pip_buf_operations struct).
When performing a normal write to a pipe, it occurs as follows:
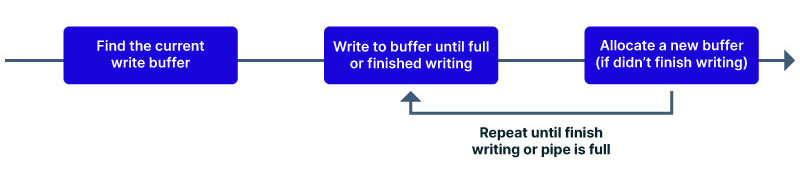
As is shown in the normal behavior diagram, if there is a space left in a buffer new data will be written into it. However, this may be problematic with the zero-copy concept. As mentioned, the zero-copy operation copies the reference to the file’s page. If a page reference is copied this way, the pipe must prevent it from being modified or it will have to copy the whole page instead of just the pointer. Thus, the normal write behavior must be modified to protect it. Therefore, a flag was introduced to specify if new data could be written to the buffer or not – PIPE_BUF_FLAG_CAN_MERGE (to be referred as CAN_MERGE flag in this article). From kernel 5.8 this flag became part of the series of flags of the pipe_buffer struct.
With this, we can add a new stage to the writing process:
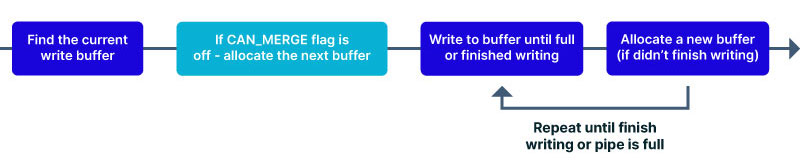
Seems good.
When Splice Go Wrong
As explained in the previous section, when copying a page using a zero-copy operation, only that page’s reference is copied. This means that, as a result, one file (a pipe in our case) holds a reference to a page belonging to another file. Except for the reference, there is no real connection between the page and the pipe (unlike the original file that the page is connected to).
So, what can go wrong with the zero-copy splice operation?
The problem is that when the CAN_MERGE flag became part of the pipe_buffer struct (back in kernel 5.8), not all the ways to allocate a new buffer initialized the flags. It was probably far less important before this flag was included so it managed to go unnoticed. One of the places that missed the initialization of the flags was the splice implementation, in the copy_page_to_iter_pipe function as well as in the push_pipe function.
This means that when performing splice, which copies a reference to the read file’s page, the page is not protected from modification. The protection of the page would depend on the previous value of the CAN_MERGE flag according to the previous data written to the same buffer before.
So, how did this go unnoticed?
The CAN_MERGE flag must be set to modify the page. However, by default all flags are unset. To be able to modify a page inside a pipe_buffer, an operation which sets the CAN_MERGE flag must occur to the buffer before the splice. But splice copies an entire page. Therefore, for this operation to have the desired effect the splice must come after writing to all the buffers and then returning to the first one (through the ring architecture of the buffers). What are the odds that some application will use both normal arbitrary write and splice on the same pipe and write enough data to go over all the pipe buffers until the same buffer return in the ring?
Evidently, not very high.
Dirty Pipe Exploitation
So, how do you implement the dirty pipe exploit?
Pretty easily.
You simply write arbitrary data to fill the whole pipe buffers – data with CAN_MERGE permissions. Then use splice to copy at least 1 byte from a file to the pipe, and ta-da! Your next write will modify the page containing the spliced location!
This will result in the file’s page-cache being modified. Since this isn’t a normal write, there wouldn’t be a sync with the disk to modify it there (unless another program modifies the same page to force a sync). But, for every other use during the same boot, the file is modified.
This means you only need to be able to read the file to modify it. You don’t need write permissions, and you’re not vulnerable to other methods that prevent file modification.
There are limits to this CVE:
- The exploit must write at least 1 byte, so the first byte of each page in a file cannot be modified (including the first byte of the file).
- For each use of the exploitation, only 1 page can be modified (though someone could simply run the same operation again without consequences).
- The file’s size cannot be modified – the file knows what range of data it uses in each page. The inode’s data must be changed to do this.
- You need to be able to read the file. This means you need access to it (by mount namespace), and you need to be able to open it with read permissions.
What’s Different about this Exploit?
The significance of this exploitation is that there is no indication that any write has been committed to the file. The approach of changing the file with this exploit does not correspond to any normal file modification method:
- Use a file write operation of a file struct (
write, write_iter, splice_write, etc.) - Mmap memory of a file to a program and modifying it there.
This means that if you don’t check the file content regularly to detect a change, you won’t be aware that any file modification has occurred. This is a major issue in the real time protection world.
However, when exploitation details are clear while using in-kernel visibility, it’s possible to monitor the exploitation file modification.
Detecting Dirty Pipe Exploitation Writes
In this part we will discuss how exploitation can be detected when used by an in-kernel hooking engine like kernel module or an eBPF program.
The exploitation must use splice resulting in an unprotected pipe buffer, then write to that unprotected buffer. By hooking on the splice syscall, we can monitor such a splice operation.
A hook is placed upon the implementation of the splice syscall – the do_splice function. This hook gives insight into both file arguments given to the function – the input file and the output pipe.
The program registered to this hook checks the result of the syscall. To do this, it uses a kretprobe which is triggered upon the function return. It checks the following things:
- Is the output file a pipe?
- Is the
CAN_MERGEflag set for the current (after splice) input page?
To do this, the program will need to determine what type of output file it is. This can be done in multiple ways, but the easiest one is probably to check if the file_operations struct member address is the address of pipe’s file operations struct. After confirming the output file is a pipe, the program accesses the pipe struct, finds the current input buffer, accesses its flags, and checks the CAN_MERGE flag.
This way, the program can determine if the exploitation has occurred.
If the exploitation is used, the program can utilize its internal access to the input file and the pipe to determine which file is vulnerable to modification as well as the range of data exposed.
With information like this, a researcher can determine the attacker’s intentions in using this vulnerability. This is very powerful information because, as we discussed, no normal real-time monitoring method could access this information without kernel access and a deep understanding of the pipe struct.
Note that this exploitation could occur mistakenly by a busy server (like the original CVE disclosure). This means that a pipe with a vulnerable buffer isn’t a deterministic sign for attack on the machine.
Below is an example of catching splice resulting in an unprotected file’s page reference in a pipe using the eBPF tool Tracee:
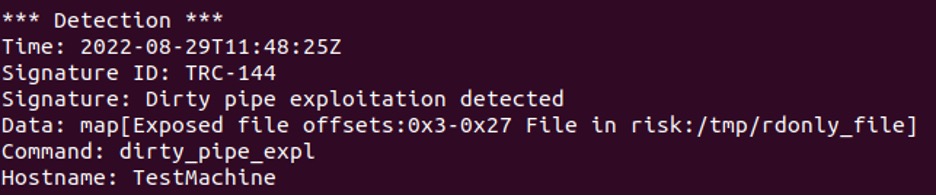
For more implementation information, please take a look at Tracee’s source code at the implementation of the dirty_pipe_splice event.
Summary
In this paper we reviewed the flow of events which result in the Dirty Pipe vulnerability. We discussed the exploit implementation, of how things look and happen in the kernel. We explained why this exploitation is more dangerous than that it may seem due to unmonitored write it produces. Finally, we detailed how with an in-kernel view of functions using technology like eBPF we can monitor writes using the exploit as well as the write content.
Mitigation
If you have vulnerable kernel version (5.8 or later), make sure to update it to the latest version in which the exploit was fixed – 5.10.102, 5.15.25 or 5.16.11.
To secure your environment even in unprotected versions, we advise using Aqua’s runtime protection CNDR which can detect this exploitation.
